یک تراشه شتابدهنده جدید به نام «Hiddenite» توسط محققان توکیو Tech ساخته شده است، که میتواند با دقتی پیشرفته در محاسبه پراکنده با بار محاسباتی کمتر به «شبکههای عصبی پنهان» دست یابد.
تراشه Hiddenite { مخفف Hidden Neural Inference Tensor Engine } با استفاده از ساخت مدل پیشنهادی روی تراشه، که ترکیبی از تولید وزن و گسترش "supermask" است، دسترسی به حافظه خارجی را برای افزایش کارایی محاسباتی به شدت کاهش می دهد.
شبکههای عصبی عمیق (DNN)} DotNetNuke یک سیستم مدیریت محتوای وب و چارچوب برنامه کاربردی وب بر اساس است{ یک قطعه پیچیده از معماری یادگیری ماشین برای هوش مصنوعی (یادگیری مصنوعی) هستند که برای یادگیری پیشبینی خروجیها به پارامترهای متعددی نیاز دارند. با این حال، DNN ها را می توان جدا کرد و در نتیجه بار محاسباتی و اندازه مدل را کاهش داد.
چند سال پیش، «فرضیه lottery ticket hypothesis -بلیت بخت آزمایی» دنیای یادگیری ماشینی را تحت تأثیر قرار داد. این فرضیه بیان کرد که یک DNN به طور تصادفی اولیه حاوی زیرشبکه هایی است که پس از آموزش به دقتی معادل DNN اصلی می رسد.. هرچه شبکه بزرگتر باشد، «بلیت های قرعه کشی» بیشتر برای بهینه سازی موفقیت آمیز است. بنابراین، این بلیتهای بختآزمایی به شبکههای عصبی پراکنده «جدا شده» اجازه میدهند تا به دقتهایی معادل شبکههای پیچیدهتر و متراکم دست یابند و در نتیجه بار محاسباتی و مصرف برق کلی را کاهش دهند.
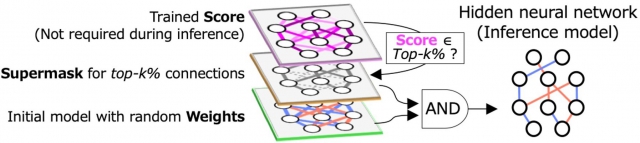
یکی از تکنیکها برای یافتن چنین زیرشبکههایی، الگوریتم شبکه عصبی پنهان (HNN) است که از منطق AND (که در آن خروجی تنهازمانی بالاست که همه ورودیها بالا هستند) روی وزنهای تصادفی اولیه و یک «ماسک دودویی» به نام «سوپرماسک» استفاده میکند. سوپر ماسک که با بالاترین امتیاز k٪ تعریف شده است، اتصالات انتخاب نشده و انتخاب شده را به ترتیب 0 و 1 نشان می دهد. HNN از نظر نرم افزار به کاهش کارایی محاسباتی کمک می کند. با این حال، محاسبات شبکه های عصبی نیز نیازمند بهبود در اجزای سخت افزاری است.
شتاب دهنده های DNN سنتی عملکرد بالایی دارند، هرچندکه مصرف برق ناشی از دسترسی به حافظه خارجی را در نظر نمی گیرند
. اکنون، محققان مؤسسه فناوری توکیو (Tokyo Tech) به رهبری پروفسورهای Jaehoon Yu و Masato Motomura، یک تراشه شتاب دهنده جدید به نام "Hiddenite" ساخته اند که می تواند شبکه های عصبی پنهان را با مصرف انرژی به شدت بهبود یافته محاسبه کند.، و به نوعی کاهش دسترسی به حافظه خارجی کلید کاهش مصرف انرژی است. در حال حاضر، دستیابی به دقت استنتاج(نتیجه گیری) بالا، نیازمند مدل های بزرگ است. اما این دسترسی حافظه خارجی به پارامترهای مدل بارگذاری را افزایش می دهد. پروفسور موتومورا توضیح می دهد که انگیزه اصلی ما در پشت توسعه Hiddenite این بود که دسترسی به حافظه خارجی را کاهش دهیم. مطالعه آنها در کنفرانس بین المللی مدارهای حالت جامد آینده (ISSCC) 2022، یک کنفرانس بین المللی معتبر که اوج موفقیت در مدارهای مجتمع را به نمایش می گذارد، ارائه می شود.
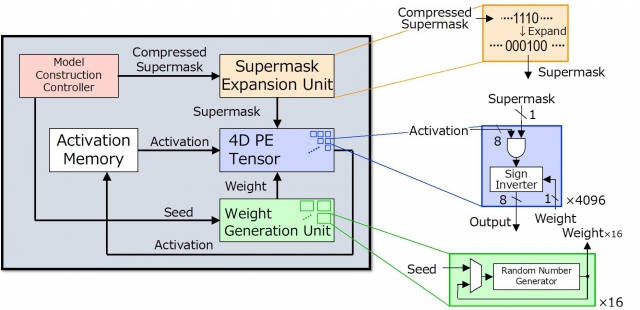
اولین تراشه استنتاج HNN است. معماری Hiddenite مزایای سه گانه ای را برای کاهش دسترسی به حافظه خارجی و دستیابی به بهره وری انرژی بالا ارائه می دهد. اولین مورد این است که تولید وزن روی تراشه را برای تولید مجدد وزن ها با استفاده از یک تولید کننده اعداد تصادفی ارائه می دهد. این امر نیاز به دسترسی به حافظه خارجی و ذخیره وزنه ها را از بین می برد. مزیت دوم، ارائه «گسترش سوپر ماسک روی تراشه» است که تعداد سوپر ماسکهایی را که باید توسط شتابدهنده بارگیری شوند، کاهش میدهد. سومین پیشرفت ارائه شده توسط تراشه Hiddenite، پردازنده موازی چهار بعدی (4 بعدی) با چگالی بالا است که استفاده مجدد از داده ها را در طول فرآیند محاسباتی به حداکثر می رساند و در نتیجه کارایی را بهبود می بخشد.

پروفسور موتومورا می گوید: «دو عامل اول چیزی است که چیپ Hiddenite را از شتاب دهنده های استنتاج DNN موجود متمایز می کند. علاوه بر این، ما همچنین یک روش آموزشی جدید برای شبکههای عصبی پنهان به نام «تقطیر امتیازی» معرفی کردیم که در آن وزنهای تقطیر دانش، مرسوم در امتیازات تقطیر میشونداین امر به این علت است که شبکههای عصبی پنهان هرگز وزنها را بهروزرسانی نمیکنند. دقت استفاده از تقطیر امتیاز با مدل باینری قابل مقایسه است در حالی که اندازه آن نصف مدل باینری است.
بر اساس معماری hiddenite، تیم یک تراشه اولیه را با فرآیند 40 نانومتری شرکت تولید نیمه هادی تایوان (TSMC) طراحی، ساخت و اندازه گیری کرده است. این تراشه تنها 3 میلیمتر در 3 میلیمتر است و 4096 عملیات MAC (تکثیر و انباشته) را به طور همزمان انجام میدهد. این دستگاه به سطح پیشرفتهای از راندمان محاسباتی، تا 34.8 تریلیون یا ترا عملیات در ثانیه (TOPS) به ازای هر وات توان دست مییابد، در حالی که میزان انتقال مدل را به نصف شبکههای باینریزه شده کاهش میدهد.
این یافتهها و نمایش موفقیتآمیز آنها در یک تراشه سیلیکونی واقعی مطمئناً باعث تغییر پارادایم{ مجموعهای از الگوها و نظریهها را برای یک گروه یا یک جامعه شکل دادهاند.} دیگری در دنیای یادگیری ماشینی میشود و راه را برای محاسبات سریعتر، کارآمدتر و در نهایت سازگارتر با محیط هموار میکند.
های فن تک از شما دعوت می کند نظرات خود را در مورد این مقاله به اشتراک بگذارید